Rethinking ETL: How Apache Flink Transformed Our Data Pipeline

I’m a Software Developer with a strong foundation in building scalable, accessible, and inclusive products across both early-stage startups and enterprise environments. My experience spans backend-heavy systems, real-time data pipelines, and internal tooling that drives measurable impact.
I currently work at WorkIndia as a Software Development Engineer, where I help design and build robust backend systems, real-time data pipelines, and automation tools that power one of India’s largest job platforms. Previously, I interned at Microsoft and Raven (YC S22), where I contributed to building end-to-end, production-ready features that significantly improved product performance and operational efficiency.
Outside of work, I’m building Evolv, a fitness app designed to go beyond tracking, helping users build intentional workout rituals backed by meaningful insights. It’s been an exciting journey bringing product thinking and engineering together to solve a deeply personal problem.
🧠 Leadership & Mentorship Mentoring junior developers and interns, helping them grow technically and align with real-world engineering best practices.
💡 Community & Communication Beyond code, I’m a people-first engineer. I’ve led developer communities, such as the Google Developer Student Club at university, scaling it to over 2,000 members. I’ve spoken at tech events and enjoy sharing ideas, whether through talks or writing. I also maintain a blog where I explore both the technical and human side of software development.
🛠️ Technical Interests Backend systems • Event-driven architecture • Real-time data pipelines • Internal developer tools • Automation • Platform thinking
Introduction
In today’s data-first landscape, organizations are under increasing pressure to make decisions in real time. While traditional batch ETL systems have served us well, they come with inherent limitations — data latency, operational complexity, and resource inefficiency. We faced this challenge head-on: a legacy ETL system with fixed batch windows, stale data, and brittle pipelines.
This post outlines our journey of replacing an aging batch ETL pipeline with Apache Flink, a powerful stream processing engine that enabled real-time data availability, lowered costs, and simplified our architecture.
The Bottlenecks of Batch ETL
We began with a conventional batch architecture that processed various datasets through scheduled jobs executed every 24 hours. Over time, this setup became a bottleneck due to several critical issues:
Data Latency: Business decisions were based on data that was already stale by the time it was available.
Resource Spikes: Heavy jobs ran in parallel during narrow time windows, leading to massive load peaks and under-utilized resources the rest of the day.
Maintenance Overhead: Each pipeline had its own logic, scheduling, monitoring, and alerting mechanisms.
Poor Scalability: Scaling batch pipelines meant increasing compute power, which only delayed job runtimes further.
Data Drift and Inconsistency: Syncing logic across multiple pipelines was error-prone and fragile.
We realized this architecture could no longer support the dynamic, high-volume, low-latency data demands of our organization.
Why Apache Flink?
We evaluated multiple stream processing frameworks, including Apache Spark Streaming, Kafka Streams, and Flink. Apache Flink stood out due to its architectural elegance and maturity in stream-first processing.
Stream-First Architecture: Unlike micro-batch engines, Flink operates on true streams. Every event is processed as it arrives, unlocking low-latency computation.
Exactly-Once Semantics: Flink’s stateful stream processing and checkpointing give strong consistency guarantees.
Backpressure Management: Flink automatically detects slow downstream operators and propagates backpressure to throttle the source, preventing overload.
Rich SQL & CEP Support: Flink offers powerful abstractions for developers and analysts, including SQL, Table API, and Complex Event Processing.
Unified Batch + Stream API: Flink handles batch as a special case of streaming, reducing cognitive load and allowing us to gradually migrate legacy jobs.
New Architecture: Event-Driven and Stream-Native
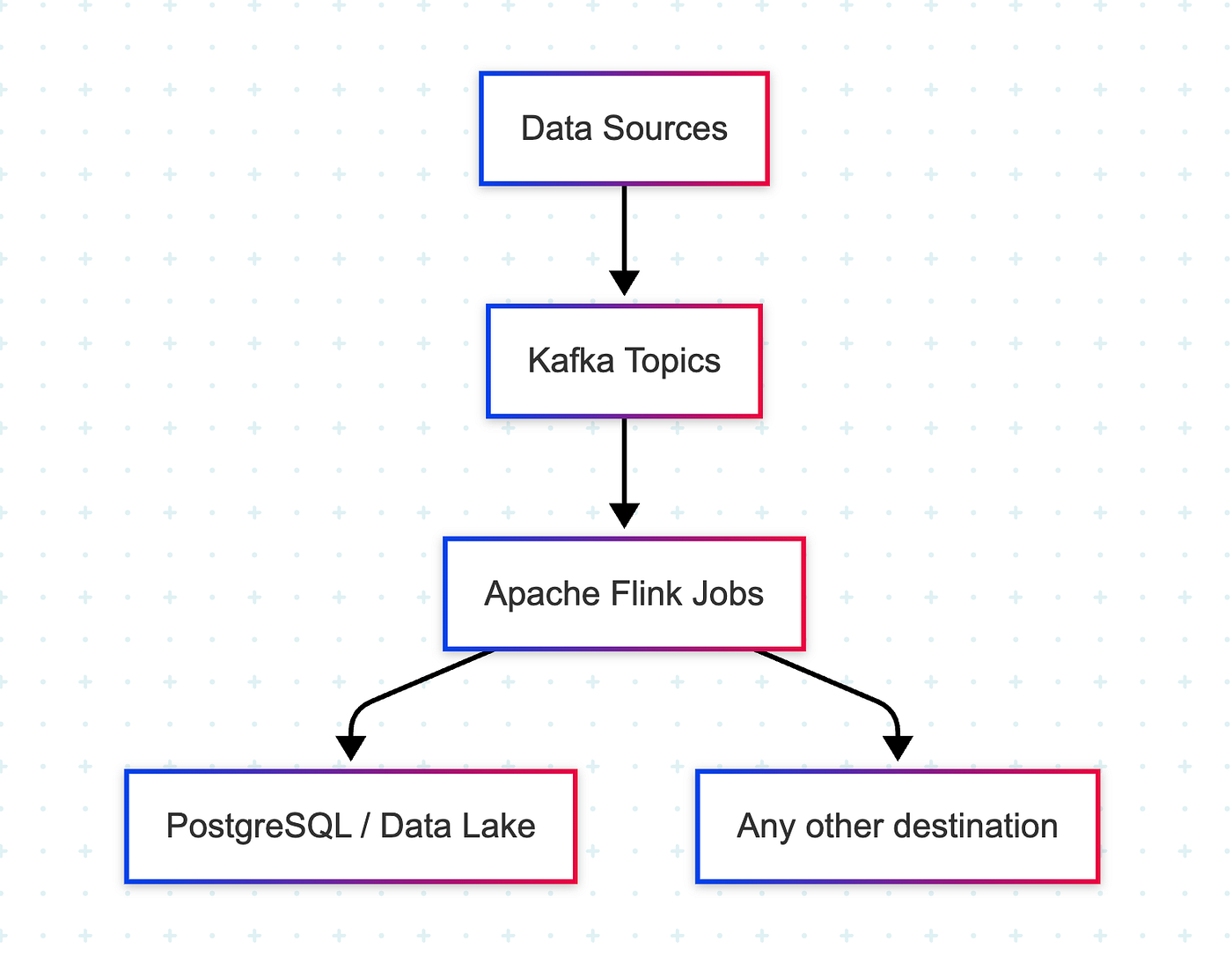
Our reimagined data platform includes three key components:
Kafka: Acts as the event buffer, decoupling producers and consumers. All incoming data (logs, transactions, events) is published to Kafka topics.
Apache Flink: The heart of the system. We built multiple Flink jobs, each consuming one or more topics, performing enrichment, validation, filtering, aggregations, and joining across streams.
PostgreSQL: Used as the final sink for storing processed and transformed data, which is then used by downstream analytics tools and internal dashboards.
Each Flink job runs continuously and reacts to data as it arrives, providing near-instant availability of information.
How Flink Solved Our Pain Points
The shift to Apache Flink addressed our major pain points:
Latency Dropped from Hours to Seconds: Business metrics and KPIs are now updated in real-time, enabling operational decisions based on the current state.
Smarter Resource Utilization: Instead of concentrating all compute in a nightly window, Flink distributes compute needs evenly throughout the day.
Unified Pipelines: We now manage significantly fewer jobs, each built on a shared abstraction with common monitoring and alerting.
Scalability by Design: Adding a new stream or increasing throughput is as simple as scaling Flink clusters horizontally.
Improved Data Quality: With built-in stateful processing, we implemented deduplication, out-of-order handling, and anomaly detection within the stream jobs.
Impact Metrics
The impact of the migration was measurable and immediate:
Latency: Reduced from 24 hours to sub-10 seconds
Throughput: 5x increase in events handled per second
Infrastructure Cost: 30% reduction in compute costs due to even load distribution
Operational Load: 50% fewer on-call alerts and data quality incidents
Conclusion
Transitioning from batch ETL to Apache Flink was not just a technical upgrade — it was a paradigm shift. We moved from passive, delayed insights to a proactive, real-time data ecosystem.
Flink enabled us to build a system that is not only faster and cheaper but also fundamentally better suited to the dynamic nature of modern data.
If you’re operating with stale data and struggling with complex batch jobs, it might be time to consider the real-time revolution. We did — and we’re not looking back.